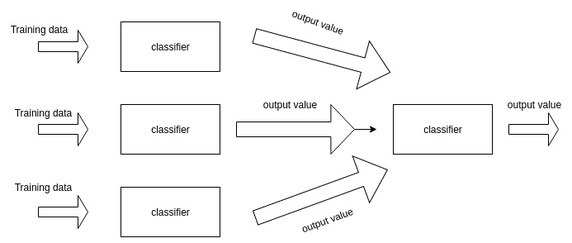
■ 스태킹 앙상블의 개요
- 스태킹(Stacking)은 개별적인 여러 알고리즘을 서로 결합해 예측 결과를 도출한다는 점에서 배깅(Bagging), 부스팅(Boosting)과 공통점을 가짐
- 하지만, 개별 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행한다는 큰 차이점을 가짐

- 이 때, 기반 모델들이 예측한 값을 통해 메타 모델이 이를 학습하고 예측하는 모델
- 스태킹 모델의 핵심은 여러 개별 모델의 예측 데이터를 각각 스태킹 형태로 결합해 최종 메타 모델의 학습용 피처 데이터 세트와 테스트용 피처 데이터 세트를 만드는 것
■ 스태킹 앙상블의 구체적인 프로세스 with python
위스콘신 암 데이터 세트에 기본 스태킹 모델을 적용해본다.
- 데이터 로딩 후 학습/테스트 데이터로 분할
# 필요한 모듈 불러오기
import numpy as np
from sklearn.neightbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 데이터 불러오기
cancer_data = load_breast_cancer()
X_data = cancer_data.data
y_label = cancer_data.target
# 학습/테스트 데이터셋 분리
X_train, X_test, y_train, y_test = train_test_split(X_data, y_label, test_size = 0.2, random_state = 0)
- 스태킹에 사용될 머신러닝 알고리즘 클래스를 생성
- 개별 모델(기반모델) : KNN, 랜덤 포레스트, 결정 트리, 에이다부스트
- 최종 모델(메타모델) : 로지스틱 회귀
# 개별 ML 모델 생성 (=> 기반모델)
knn_clf = KNeighborsClassifier(n_neighbors = 4)
rf_clf = RandomForestClassifier(n_estimators = 100, random_state = 0)
dt_clf = DecisionTreeClassifier()
ada_clf = AdaBoostClassifier(n_estimators = 100)
# 스태킹으로 만들어진 데이터 세트를 학습, 예측할 최종 모델 (=> 메타모델)
lr_final = LogisticRegression()
- 개별 모델 학습
# 개별 모델 학습
knn_clf.fit(X_train, y_train)
rf_clf.fit(X_train, y_train)
dt_clf.fit(X_train, y_train)
ada_clf.fit(X_train, y_train)
- 개별 모델의 예측 데이터 세트 반환 및 각 모델의 예측 정확도 확인
# 학습된 개별 모델들이 각자 반환하는 예측 데이터 세트를 생성하고 개별 모델의 정확도 측정
knn_pred = knn_clf.predict(X_test)
rf_pred = rf_clf.predict(X_test)
dt_pred = dt_clf.predict(X_test)
ada_pred = ada_clf.predict(X_test)
gbm_pred = gbm_clf.predict(X_test)
print('KNN 정확도 : {0:.4f}'.format(accuracy_score(y_test, knn_pred)))
print('랜덤 포레스트 정확도 : {0:.4f}'.format(accuracy_score(y_test, rf_pred)))
print('결정 트리 정확도 : {0:.4f}'.format(accuracy_score(y_test, dt_pred)))
print('에이다부스트 정확도 : {0:.4f}'.format(accuracy_score(y_test, ada_pred)))
- 예측값을 이용해 메타모델에서 사용하기 위한 학습 데이터를 생성
pred = np.array([knn_pred, rf_pred, dt_pred, ada_pred])
print(pred.shape) # (4, 114) => 전치해야 함
# transpose를 이용해 행과 열의 위치 교환
# 칼럼 레벨로 각 알고리즘의 예측 결과를 피처로 만듦
pred = np.transpose(pred)
print(pred.shape) # (114, 4)
- 최종 메타 모델인 로지스틱 회귀를 학습 및 예측 정확도 측정
lr_final.fit(pred, y_test)
final = lr_final.predict(pred)
print('최종 메타 모델의 예측 정확도 : {0:.4f}'.format(accuracy_score(y_test, final)))
■ CV 세트 기반의 스태킹
- 앞 예제에서 메타 모델인 로지스틱 회귀 모델 기반에서 최종 학습 시 레이블 데이터 세트로 학습 데이터가 아닌 테스트용 레이블 데이터 세트를 기반으로 학습하여 과적합 문제가 발생할 수 있음
- CV 세트 기반의 스태킹은 이를 개선하기 위해 개별 모델들이 각각 교차 검증으로 메타 모델을 위한 학습용 스태킹 데이터 생성과 예측을 위한 테스트용 스태킹 데이터를 생성한 뒤 이를 기반으로 메타 모델이 학습과 예측을 수행
- 스텝 1: 각 모델별로 원본 학습/테스트 데이터를 예측한 결과 값을 기반으로 메타 모델을 위한 학습/테스트 데이터를 생성
- 스텝 2: 스텝 1에서 개별 모델들이 생성한 학습용 데이터를 모두 스태킹 형태로 합쳐서 메타 모델이 학습할 최종 학습용 데이터 세트를 생성. 마찬가지로 각 모델들이 생성한 테스트용 데이터를 모두 스태킹 형태로 합쳐서 메타 모델이 예측할 최종 데이터 세트를 생성. 메타 모델은 최종적으로 생성된 학습 데이터 세트와 원본 학습 데이터의 레이블 데이터를 기반으로 학습한 뒤, 최종적으로 생성된 테스트 데이터 세트를 예측하고, 원본 테스트 데이터의 레이블 데이터를 기반으로 평가함
■ CV 세트 기반의 스태킹 과정 도식화
1. 교차 검증 세트 기반 스태킹 모델 만들기 - K Fold 첫 번째

2. 교차 검증 세트 기반 스태킹 모델 만들기 - K Fold 두 번째

3. 교차 검증 세트 기반 스태킹 모델 만들기 - K Fold 세 번째

4. 교차 검증 세트 기반 스태킹 모델 만들기 - 최종

■ CV 세트 기반의 스태킹 모델 실습 with python
- 개별 모델이 메타 모델을 위한 학습용 데이터와 테스트 데이터를 생성
from sklearn.model_selection import KFold
from sklearn.metrics import mean_absolute_error
# 개별 기반 모델에서 최종 메타 모델이 사용할 학습 및 테스트용 데이터를 생성하기 위한 함수
def get_stacking_base_datasets(model, X_train_n, y_train_n, X_test_n, n_folds):
# 지정된 n_folds 값으로 KFold 생성
kf = KFold(n_splits = n_folds, shuffle = False)
# 추후에 메타 모델이 사용할 학습 데이터 반환을 위한 넘파이 배열 초기화
train_fold_pred = np.zeros((X_train_n.shape[0], 1)) # 개별 모델 기준
test_pred = np.zeros((X_test_n.shape[0], n_folds)) # 개별 모델 기준
print(model.__class__.__name__, 'model 시작')
for folder_counter, (train_index, valid_index) in enumerate(kf.split(X_train_n)):
# 입력된 학습 데이터에서 기반 모델이 학습/예측할 폴드 데이터셋 추출
print('\t 폴드 세트 :', folder_counter, '시작')
X_tr = X_train_n[train_index]
y_tr = y_train_n[train_index]
X_te = X_train_n[valid_index]
# 폴드 세트 내부에서 다시 만들어진 학습 데이터로 기반 모델의 학습 수행
model.fit(X_tr, y_tr)
# 폴드 세트 내부에서 다시 만들어진 검증 데이터로 기반 모델 예측 후 데이터 저장
train_fold_pred[valid_index, :] = model.predict(X_te).reshape(-1, 1)
# 입력된 원본 테스트 데이터를 폴드 세트 내 학습된 기반 모델에서 예측 후 데이터 저장
test_pred[:, folder_counter] = model.predict(X_test_n)
# 폴드 세트 내에서 원본 테스트 데이터를 예측한 데이터를 평균하여 테스트 데이터로 생성
test_pred_mean = np.mean(test_pred, axis = 1).reshape(-1, 1)
# train_fold_pred는 최종 메타 모델이 사용하는 학습 데이터, test_pred_mean은 테스트 데이터
return train_fold_pred, test_pred_mean # 추후에 개별 모델 전부 수행 후 이를 합쳐야 함
- 여러 개의 분류 모델별로 stack_base_model() 함수 수행
knn_train, knn_test = get_stacking_base_datasets(knn_clf, X_train, y_train, X_test, 7)
rf_train, rf_test = get_stacking_base_datasets(rf_clf, X_train, y_train, X_test, 7)
dt_train, dt_test = get_stacking_base_datasets(dt_clf, X_train, y_train, X_test, 7)
ada_train, ada_test = get_stacking_base_datasets(ada_clf, X_train, y_train, X_test, 7)
- 각 모델별 학습 데이터와 테스트 데이터 합치기
Stack_final_X_train = np.concatenate((knn_train, rf_train, dt_train, ada_train), axis = 1)
Stack_final_X_test = np.concatenate((knn_test, rf_test, dt_test, ada_test), axis = 1)
print('원본 학습 피처 데이터 Shape:', X_train.shape, '원본 테스트 피처 Shape :', X_test.shape) # (455, 30), (114, 30)
print('스태킹 학습 피처 데이터 Shape :', Stack_final_X_train.shape, '스태킹 테스트 피처 데이터 Shape :', Stack_final_X_test.shape) # (455, 4), (114, 4)
- 최종 메타 모델인 로지스틱 회귀 학습/예측/예측 성능 측정
lr_final.fit(Stack_final_X_train, y_train)
stack_final = lr_final.predict(Stack_final_X_test)
print('최종 메타 모델의 예측 정확도 : {0:.4f}'.format(accuracy_score(y_test, stack_final)))
- 본 포스팅은 파이썬 머신러닝 완벽 가이드를 참고하여 작성하였습니다.
'Python > Data Analysis' 카테고리의 다른 글
| [Pandas] 머신러닝 데이터 분석 (0) | 2022.04.13 |
|---|